User Guide¶
This is a comprehensive guide to deploying a ML pipelines to Kubernetes. It assumes that you understand the key concepts that Bodywork is built upon and that you have worked through one of the Quickstart Tutorials.
Before we get Started¶
Startup a Kubernetes cluster and configure it for use with Bodywork,
$ bw configure-cluster
Structuring a ML Pipeline Project¶
Bodywork does not impose constraints on how you structure or develop your pipelines. So long as each stage in a pipeline can be linked to an executable Python module (or Jupyter notebook), then all Bodywork requires is configuration data contained within a file called bodywork.yaml. This YAML file describes how Bodywork should deploy the pipeline and will be the main focus of this user guide.
As an example scenario that we will refer back to throughout this guide, consider the following project structure for a ML pipeline with the following stages: prepare features, train models (one using a SVM and another using a random forest), select the best performing model, and then deploy a microservice to serve predictions from the chosen model (via a REST API):
root/
|-- prepare_data/
|-- prepare_data.py
|...
|-- train_svm/
|-- train_svm.py
|...
|-- train_random-forest/
|-- train_random_forest.py
|...
|-- choose_model/
|-- choose_model.py
|...
|-- prediction_service/
|-- flask_prediction_api.py
|...
|-- raise_alerts.py
|-- bodywork.yaml
We have chosen to split the project into five directories, one for each stage, but this is not a requirement. The pipeline configuration in bodywork.yaml is shown below:
version: "1.1"
pipeline:
name: classification-pipeline
docker_image: bodyworkml/bodywork-core:latest
DAG: prepare_features >> train_svm, train_random_forest >> choose_model >> prediction_service
run_on_failure: send_notifications
secrets_group: dev
stages:
prepare_features:
executable_module_path: prepare_features/prepare_features.py
requirements:
- boto3==1.16.15
- pandas==1.1.4
cpu_request: 0.5
memory_request_mb: 100
batch:
max_completion_time_seconds: 30
retries: 2
train_svm:
executable_module_path: train_svm/train_svm.py
requirements:
- boto3==1.16.15
- pandas==1.1.4
- joblib==0.17.0
- scikit-learn==0.23.2
cpu_request: 1.0
memory_request_mb: 500
batch:
max_completion_time_seconds: 120
retries: 2
train_random_forest:
executable_module_path: train_random_forest/train_random_forest.py
requirements:
- boto3==1.16.15
- pandas==1.1.4
- joblib==0.17.0
- scikit-learn==0.23.2
cpu_request: 2.0
memory_request_mb: 750
batch:
max_completion_time_seconds: 120
retries: 2
choose_model:
executable_module_path: choose_model/choose_model.py
requirements:
- boto3==1.16.15
- joblib==0.17.0
- numpy==1.19.4
- scikit-learn==0.23.2
cpu_request: 0.5
memory_request_mb: 100
batch:
max_completion_time_seconds: 60
retries: 2
prediction_service:
executable_module_path: prediction_service/flask_prediction_api.py
args: ["30", "ABC"]
requirements:
- Flask==1.1.2
- joblib==0.17.0
- numpy==1.19.4
- scikit-learn==0.23.2
secrets:
USERNAME: cloud-storage-credentials
PASSWORD: cloud-storage-credentials
cpu_request: 0.25
memory_request_mb: 100
service:
max_startup_time_seconds: 30
replicas: 2
port: 5000
ingress: true
send_notifications:
executable_module_path: raise_alerts.py
requirements:
- requests==2.22.0
cpu_request: 0.5
memory_request_mb: 100
batch:
max_completion_time_seconds: 30
retries: 1
logging:
log_level: INFO
Packaging for Remote Execution¶
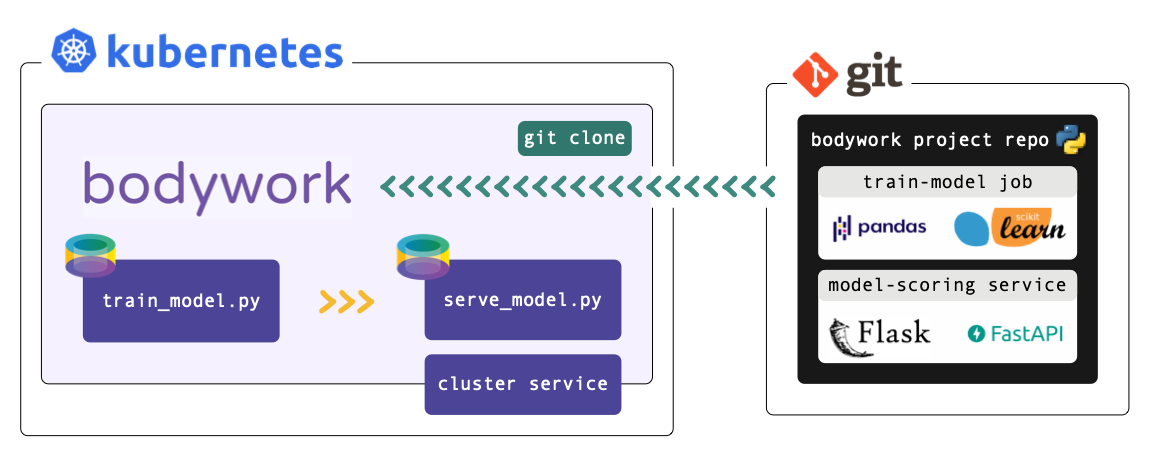
Bodywork projects must be packaged as Git repositories, hosted on one of the following services: GitHub, GitLab, Azure DevOps or BitBucket. When a deployment is triggered, Bodywork will clone the repository, analyse the configuration provided in bodywork.yaml, and then orchestrate the execution of each stage in the pipeline.
Each stage is executed within a newly created Python-enabled container, that starts by installing any 3rd party Python package dependencies that have been specified in bodywork.yaml, before running the chosen Python module (or Jupyter notebook).
Configuring Pipelines¶
High-level configuration for the pipeline is contained within the project section of bodywork.yaml. From the example above we have,
pipeline:
name: classification-pipeline
docker_image: bodyworkml/bodywork-core:latest
DAG: prepare_features >> train_svm, train_random_forest >> choose_model >> prediction_service
run_on_failure: send_notifications
Each configuration parameter is used as follows:
name- This will be used to label all Kubernetes resources deployed for this pipeline.
docker_image- The container image to use for remote execution of pipeline stages. This should be set the version of the Bodywork CLI that you are using - e.g.,
bodyworkml/bodywork-core:3.0.0, which will be pulled from DockerHub. You are free to create custom images that you can base on the official Bodywork Dockerfile. DAG- A description of the pipeline workflow - i.e., which stages to include in which step, and the order to run them in
run_on_failure- An optional batch stage to be run only after a pipeline fails to complete successfully - i.e., when one of its stages fails. Within this special stage's you could trigger a webhook for posting to Slack, use the Python standard library to send an e-mail, or use the Python client for your company's chosen incident response platform (e.g., PagerDuty). Note, that if Bodywork is unable to start the pipeline for any reason (e.g., your cluster cannot access the Bodywork container image), then it will not be able to run the chosen on-failure stage.
secrets_group- If pipeline stages reference secret credentials, then which group of credentials should Bodywork look in to find them - e.g., dev, prod, etc.
Workflow DAGs¶
The DAG string is used to control the execution of stages by assigning them to different steps of the workflow. Steps are separated using the >> operator and commas are used to delimit multiple stages within a single step (if this is required). Steps are executed from left to right. In the example above,
DAG=prepare_data >> train_svm, train_random_forest >> choose_model >> prediction_service
The workflow will be interpreted as follows:
- step 1: run
prepare_features; then, - step 2: run
train_svmandtrain_random_forestin separate containers, in parallel; then, - step 3: run
choose_model; and finally, - step 4: run
prediction_service.
Configuring Stages¶
Each stage is configured individually within the stages section of bodywork.yaml. For the prediction_service stage in the example above, we have,
stages:
...
prediction_service:
executable_module_path: prediction_service/flask_prediction_api.py
args: ["30", "ABC"]
requirements:
- Flask==1.1.2
- joblib==0.17.0
- numpy==1.19.4
- scikit-learn==0.23.2
secrets:
USERNAME: cloud-storage-credentials
PASSWORD: cloud-storage-credentials
cpu_request: 0.25
memory_request_mb: 100
service:
max_startup_time_seconds: 30
replicas: 2
port: 5000
ingress: true
Every stage must have either a batch or service sub-section defined, depending on whether the stage is a batch stage or service stage. If batch is selected, then the executable Python module (or Jupyter notebook) will be run as a discrete job (i.e., with a start and an end), and managed as a Kubernetes Job. If service is selected, then it is assumed that the executable module will start a long-running process (e.g., a web server), and so it will be managed as a Kubernetes Deployment, exposing a Kubernetes ClusterIP Service to enable access over HTTP.
Top-level stage configuration parameters are to be used as follows:
executable_module_path- The path to the executable Python module (or Jupyter notebook) that will be executed. Executable means that running
python flask_prediction_api.pyfrom the CLI would cause the module to run. args- An optional list of arguments to pass to the executable Python module (as strings).
requirements- An optional list of Python package dependencies that need to be installed into the Python environment, for the executable module to run successfully. This is same list that you would normally specify in a
requirements.txtfile. cpu_requestandmemory_request_mb- The compute resources to request from the cluster in order to run the stage. For more information on the units used in these parameters refer here.
The secrets sub-section is optional and is covered in more depth below.
Batch Stages¶
An example batch stage configuration for the prepare_features stage could be as follows,
stages:
prepare_features:
...
batch:
max_completion_time_seconds: 30
retries: 2
Where:
max_completion_time_seconds- Time to wait for the given task to run, before retrying or raising a workflow execution error. This must account for the time required to install all of the dependencies using Pip, that could take longer than it does on your local machine. If stages are timing-out early, then try increasing this value. This won't impact the overall time taken by the workflow, which will progress as soon as a stage is completed.
retries- Number of times to retry executing a failed stage, before raising a workflow execution error.
Service Deployment Stages¶
An example service configuration for the prediction_service stage could be as follows,
stages:
prediction_service:
...
service:
max_startup_time_seconds: 30
replicas: 2
port: 5000
ingress: true
Where:
max_startup_time_seconds- Time to wait for the service to be 'ready' and reachable. This must also account for the time required to install all of the dependencies using Pip, that could take longer than it does on your local machine. If stages are timing-out early, then try increasing this value. This won't impact the overall time taken by the workflow, that will progress as soon as a stage is completed. If a service deployment stage fails to be 'ready' when this time expires, then the deployment will be automatically rolled-back to the previous version.
replicas- Number of independent containers running the service defined in
flask_prediction_api.py. The service endpoint will automatically route requests to each replica in-turn, to spread the load evenly. port- The port to expose on the container - e.g., Flask-based services usually send and receive HTTP requests on port
5000. ingress- Whether or not to create a route (or path) from the cluster's externally-facing ingress controller, to this service. If set to
True, it will enable external requests to reach the service via the ingress controller (acting as an API gateway), with the following URL, http://CLUSTER_EXTERNAL_IP/PROJECT_NAME/STAGE_NAME- See Installing NGINX for more information on exposing services to external HTTP requests.
Injecting Secrets¶
Pipeline stages will require secret credentials whenever you wish to pull data or persist models to cloud storage, access private APIs, etc. We provide a secure mechanism for dynamically injecting credentials as environment variables within the container running a stage.
The first step in this process is to store your project's secret credentials - see Managing Credentials and Other Secrets below for instructions on how to achieve this with Bodywork.
The second step is to configure the use of this secret with the secrets sub-section of a stage's configuration. For example,
pipeline:
...
secrets_group: dev
stages:
prediction_service:
...
secrets:
USERNAME: cloud-storage-credentials
PASSWORD: cloud-storage-credentials
Will instruct Bodywork to look for values assigned to the keys USERNAME and PASSWORD, in the secret named cloud-storage-credentials, within the dev secrets group. Bodywork will then assign these secrets to environment variables within the container, called USERNAME and PASSWORD, respectively. These can then be accessed from within the stage's executable Python module - for example,
import os
if __name__ == '__main__':
username = os.environ['USERNAME']
password = os.environ['PASSWORD']
Configuring Logging¶
Logging configuration is contained within the logging section of bodywork.yaml. From the example above we have,
logging:
log_level: INFO
Where:
log_level- Must be one of:
DEBUG,INFO,WARNING,ERRORorCRITICAL. This is used to set the types of log message to stream to the standard output stream (stdout).
Validating bodywork.yaml¶
The bodywork.yaml file can be checked for errors, prior to pipeline deployment, by issuing the following command from the CLI,
$ bw validate --check-files
The optional --check-files flag will check that all executable_module_path paths map to files that exist and can be reached by Bodywork, from the root directory where bodywork.yaml is located (assumed to be current working directory). Validation errors will be printed to stdout.
Managing Secrets¶
Secret credentials will be required whenever you wish to pull data or persist models to cloud storage, or access private APIs from within a stage. We provide a secure mechanism for dynamically injecting secret credentials as environment variables into the container running a stage. Before a stage can be configured to inject a secret into its host container, the secret has to be created within the Kubernetes cluster. This is achieved from the CLI,
$ bw create secret "cloud-storage-credentials" \
--group "dev" \
--data "USERNAME=bodywork" "PASSWORD=bodywork123!"
This will store both USERNAME and PASSWORD within a Kubernetes secret resource called cloud-storage-credentials, tagged as belonging to a group of secrets named dev. To inject USERNAME and PASSWORD as environment variables within a stage, see Injecting Secrets above.
Private Git Repositories¶
When working with remote Git repos that are private, Bodywork will attempt to access them via SSH. This requires that you setup your remote Git host (e.g., GitHub), for SSH access - e.g., see this article. This process will result in the creation of a private and public key-pair to use for authenticating with your remote Git host.
You will then need to use Bodywork to pass the private SSH key to your Kubernetes cluster, as a secret credential. This easiest way to do this, is by specifying the path to the SSH key when you first deploy a pipeline - e.g.,
$ bw create deployment "git@github.com:my-github-username/classification-pipeline.git" \
--ssh PATH_TO_SSH_FILE
Where PATH_TO_SSH_FILE is usually ~/.shh/id_rsa. This will create the secret in the group set in pipeline.secrets_group, within bodywork.yaml. If no group is specified, then it will create one that matches pipeline.name.
Note, that when deploying pipelines from private Git repository, you must use the SSH protocol when specifying the Git repo's URL - e.g.,
git@github.com:my-github-username/classification-pipeline.git
As opposed to,
https://github.com/my-github-username/classification-pipeline
Get a Pipeline's Git Commit Hash¶
The Git commit hash of your pipeline can be accessed by any stage, directly from the GIT_COMMIT_HASH environment variable. This allows you to tag any artefacts produced by your pipelines, such as datasets and trained models, with the precise version of the pipeline used to create them. For example,
import os
git_hash = os.getenv('GIT_COMMIT_HASH')
model_filename = f'my-classifier--pipeline={git_hash}.pkl'
save_model(model, model_filename)
Deploying Pipelines¶
Deploying a pipeline will start a workflow-controller to manage the orchestration. For the example pipeline used throughout this user guide, the CLI command for deploying the pipeline from the default branch of a public Git repository, would be as follows,
$ bw create deployment "https://github.com/my-github-username/classification-pipeline"
If this repository were private, the command would be need to modified to,
$ bw create deployment "git@github.com:my-github-username/classification-pipeline.git" \
--ssh "$(cat ~/.shh/id_rsa)"
Assuming that the private key used to setup SSH access with GitHub is located at ~/.shh/id_rsa.
Note, that if you wanted to deploy a pipeline from a branch other than the default branch, you can set this using the --branch option.
Stopping a Pipeline¶
If you need to terminate a pipeline before it has finished executing, then you can do so gracefully by pressing CTRL + C in the terminal running Bodywork. This will immediately stop all running batch stages, roll-back any service deployments that are in progress, and return stage logs back to the terminal.
Testing Services¶
The details of any serviced associated with the pipeline, can be retrieved using,
$ bw get deployment "classification-pipeline" "prediction_service"
┏━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃ Field ┃ Value ┃
┡━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩
│ name │ prediction-service │
│ namespace │ classification-pipeline │
│ service_exposed │ True │
│ service_url │ http://prediction-service.classification-pipeline.svc.cluster.local │
│ service_port │ 5000 │
│ available_replicas │ 2 │
│ unavailable_replicas │ 0 │
│ git_url │ https://github.com/my-github-username/classification-pipeline │
│ git_branch │ master │
│ git_commit_hash │ e9df4b4 │
│ has_ingress │ True │
│ ingress_route │ /classification-pipeline/prediction-service │
└──────────────────────┴───────────────────────────────────────────────────────────────────────┘
Services are accessible via the public internet if you have installed an ingress controller within your cluster, and have set the stages.STAGE_NAME.service.ingress configuration parameter to true. If you are using Kubernetes via Minikube and our Kuberentes Quickstart guide, then this will have been enabled for you. Otherwise, services will only be accessible via HTTP from within the cluster, via the service_url.
Assuming that you are setup to access services from outside the cluster, then you can test the endpoint using,
$ curl "http://YOUR_CLUSTERS_EXTERNAL_IP/classification-pipeline/prediction_service/" \
--request POST \
--header "Content-Type: application/json" \
--data '{"x": 5.1, "y": 3.5}'
See here for instruction on how to retrieve YOUR_CLUSTERS_EXTERNAL_IP.
Deleting Services¶
Once you have finished testing, you may want to delete any services that have been created by your pipeline. To list all active services associated with a pipeline use,
$ bw get deployments "classification-pipeline"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃ Deployment Name / Service Name ┃ Git Repository URL ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩
│ classification-pipeline/prediction-service │ http://prediction-service.classification-pipeline.svc.cluster.local │
└──────────────────────────────────────────────┴─────────────────────────────────────────────────────────────────────┘
Then to delete a service use,
$ bw delete deployment "classification-pipeline" "prediction_service"
To delete all services associated with a pipeline, use,
$ bw delete deployments "classification-pipeline"
Pipeline Logs¶
All logs should start in a similar way,
======================== deploying master branch from https://github.com/my-github-username/classification-pipeline =========================
[02/20/22 22:26:28] INFO Creating k8s namespace = classification-pipeline
[02/20/22 22:26:28] INFO Creating k8s service account = bodywork-stage
[02/20/22 22:26:29] INFO Attempting to execute DAG step = [prepare_features]
[02/20/22 22:26:29] INFO Creating k8s job for stage = prepare-features
[02/20/22 22:27:27] INFO Successfully created k8s job for stage = prepare-features
...
After a stage completes, you will notice that the logs from within the container are streamed into the workflow-controller logs. For example,
-----------------------------------------------------------------------------------------------------------------------------------------------------------
---- pod logs for classification-pipeline--prepare_data
-----------------------------------------------------------------------------------------------------------------------------------------------------------
[02/20/22 22:27:27] INFO Attempting to run stage=prepare_data from master branch of repo at https://github.com/my-github-username/classification-pipeline
...
The aim of this log structure is to provide a useful way of debugging pipelines, without forcing you to integrate a complete logging solution.
Scheduling Pipelines¶
If your pipeline is executing successfully, then you can schedule orchestration to operate remotely on the cluster as a Kubernetes cronjob. For example, by issuing the following command from the CLI,
$ bw create cronjob "https://github.com/my-github-username/classification-pipeline" \
--name "daily" \
--schedule "0 * * * *" \
--retries 2
You will schedule our example project to run at midnight every day. A list of all active cronjobs can be retrieved using,
$ bw get cronjobs
┏━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃ Name ┃ Git Repository URL ┃
┡━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩
│ daily │ https://github.com/my-github-username/classification-pipeline │
└───────┴─────────────────────────────────────────────────────────────────┘
Information on a specific cronjob can be retrieved using,
$ bw get cronjob "classification-pipeline"
┏━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃ Field ┃ Value ┃
┡━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩
│ schedule │ 0 * * * * │
│ last_scheduled_time │ 2020-12-10 00:01:04+00:00 │
│ retries │ 1 │
│ git_url │ https://github.com/my-github-username/classification-pipeline │
│ git_branch │ master │
└─────────────────────┴─────────────────────────────────────────────────────────────────┘
A cronjob's execution history can be listed using,
$ bw get cronjob "daily" --history
run ID = daily-1645398960
┏━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃ Field ┃ Value ┃
┡━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━┩
│ start_time │ 2020-12-10 00:01:04+00:00 │
│ completion_time │ 2020-12-10 00:01:06+34:01 │
│ active │ False │
│ succeeded │ True │
│ failed │ False │
└─────────────────┴───────────────────────────┘
Cronjob Logs¶
The logs for each pipeline run can be retrieved be accessed using,
$ bw get cronjob daily --logs "daily-1645398960"
Which will stream logs directly to stdout.
Bodywork Analytics¶
We collect basic usage statistics to help us understand how Bodywork is used. Every time you run a workflow, Bodywork will ping a remote server to increment a counter (nothing more). We do not store any data about you or your workflows (not even your IP address). You can see the code for this here. If you wish to disable this, then set pipeline.usage_stats: false in your bodywork.yaml file.